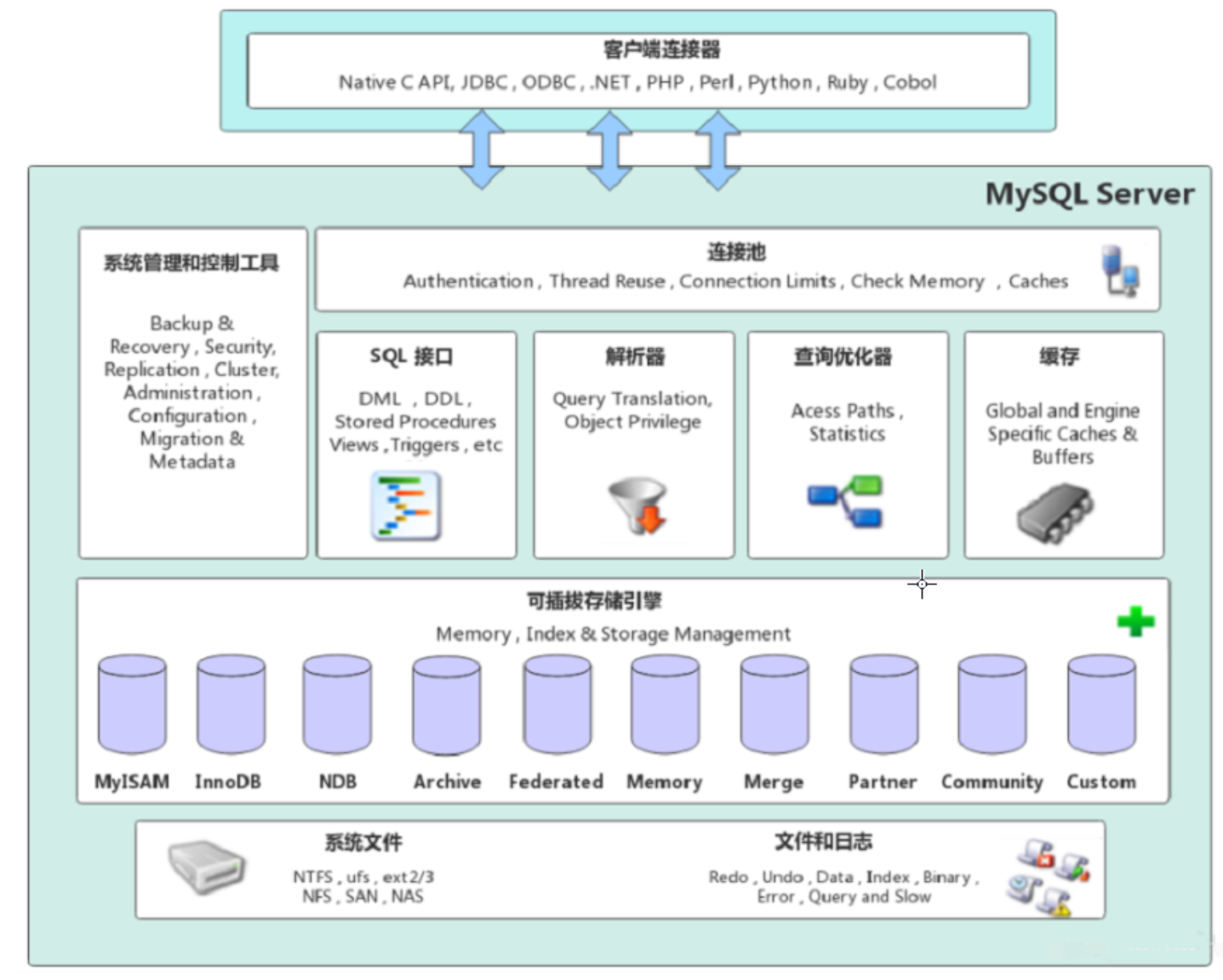
OpenAI 发布全新实时多模态模型 GPT-4o
北京时间5月14日凌晨,万众瞩目的 OpenAI 发布会正式召开,发布会全长 26分钟,虽然简短,但内容及其震撼。
如果要总结到底讲了什么事情,其实就是三件:
发布了全新的实时多模态旗舰模型 Gpt-4o(omni*),可以实时进行文本,视频和音频的推理与交互。
升级了原本的免费计划,向免费版用户提供最新的模型,且无需注册即可使用,降低了 ChatGPT 的使用门槛。
推出了客户端应用,并更新了 Web UI 界面
接下来我们就详细看下重点的第一项更新内容。
Gpt-4o
之前的 GPT-4 虽然也有语音模式,但整个语音模式的对话有着很长的时间延迟,说一句话后要等很久才有响应。并且在模型响应的过程中无法打断它并进行互动。
这是因为之前的语音模式是由三个单独的模型构成,每次用户发起语音的时候,都需要先通过模型A 将音频转换成文本,然后调用 GPT 模型处理文本,再由模型 C 来将文本转换成语音,经过 3 个步骤才能完成一次对话。
而这次全新的 GPT-4o将文本,视觉,语音都统为一个单一模型,这就相当于是所有的输入和输出都由一个模型处理,这也就是 omni 的含义,意为“所有,全方位的”。
在视频中 Mark 通过声音让 GPT4-o 给 Barrett 讲一个恋爱中的机器人为主题的睡前故事,GPT4-o 在讲述的过程中,他们并没有等到 GPT 讲完,而是轮番打断它的回答,并让 GPT 加入不同的情感,增加故事戏剧性,甚至让 GPT 通过唱歌的形式来讲故事,这些都没有难倒 GPT4-o,并且在语音交互的过程中,GTP4-o 平均300毫秒左右就能对音频输入做出反应。
实时视频
除了实时音频的能力外,GPT4-o还拥有视觉能力,这里的视觉表示它可以直接通过摄像头与我们进行交互,相当于跟 GPT 直接进行 视频聊天,在整个发布会中,演示了几个不同的实时视频场景,比如让 GPT 协助做题,总结代码,解读可视化报表,甚至官网中还有一个视觉障碍的用户那种 GPT4-o 在城市中行走。01:06
免费计划
上面的展示的这个 GPT-4o 它的价格还要比之前的 GPT4-Turbo 还要便宜一半,$5/M 的输入和$15/M的输出价格,另外在速率限制,响应速度,多语言和视觉能力都要强于 GPT4-Turbo,目前GPT-4o 的上下文限制为 128k ,知识截至为 2023年10月。
免费用户,现在所使用的 ChatGPT 默认为 GPT4-o 模型,只不过会限制消息数量,当受限后会被切换到 3.5。
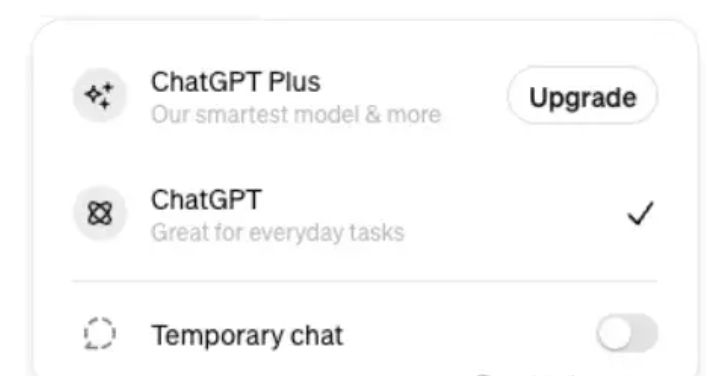
而 Plus 用户则可以自行切换不同模型,可以支持每小时 80条 GPT-4o 的消息。

至于企业版用户,则不受到消息数量限制